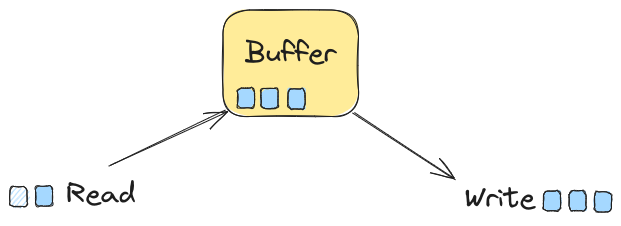
Intro Link to heading
Welcome to the final part of the Fundamentals of I/O series, where we will learn about buffered I/O. If you haven’t already, I recommend checking out the first two parts:
Before looking into I/O buffering in Go, let’s see what problems it solves.
System calls: what are they? Link to heading
When programs want to do something(e.g., open a file, send data via the network, create a process, etc.), they ask the operating system to do it via system calls(syscalls).
System calls are the API provided by the operating system to programs so they can manage resources.
These system calls are similar to regular function calls, but they involve some extra steps that cause the CPU to switch from user mode to kernel mode so it can execute a privileged action.
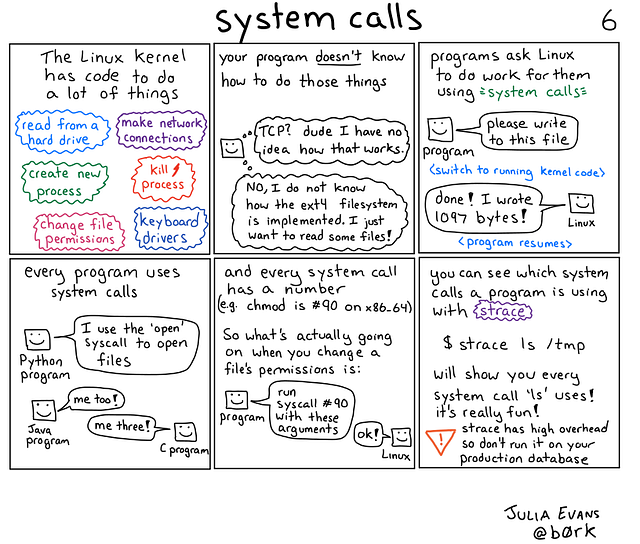
source: https://wizardzines.com/comics/syscalls/
System calls: how can we see them? Link to heading
strace is a Linux utility that lets you inspect the system calls performed by your program under the hood.
You run it with strace followed by the program you want to trace.
Say you want to trace the pwd program. strace pwd displays all the system calls performed by pwd:
execve("/usr/bin/pwd", ["pwd"], 0x7ffd23593820 /* 71 vars */) = 0
brk(NULL) = 0x61cc90c5f000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fff64ee0a80) = -1 EINVAL (Invalid argument)
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x71c13fd72000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=79587, ...}, AT_EMPTY_PATH) = 0
mmap(NULL, 79587, PROT_READ, MAP_PRIVATE, 3, 0) = 0x71c13fd5e000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
----
getcwd("/home/andrei", 4096) = 13
newfstatat(1, "", {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x3), ...}, AT_EMPTY_PATH) = 0
write(1, "/home/andrei\n", 13/home/andrei
) = 13
close(1) = 0
close(2) = 0
exit_group(0) = ?
This output can be pretty verbose because, most of the time, you don’t want to see all the syscalls. You can filter for a specific syscall by using the -e option.
For example, to see only the write system calls we run:
strace -e write pwd
Running this on my home directory, I get the following output:
write(1, "/home/andrei\n", 13/home/andrei
) = 13
+++ exited with 0 +++
which means that the 13 bytes of /home/andrei\n are successfully written to file with the descriptor 1 (the standard output in Linux). That’s all you need to know for this article, but if you want to learn more, check out this zine made by Julia Evans.
I like strace because it helps me see what a program is doing even if I can’t access the source code. Some people call strace the Sysadmin’s Microscope, but I view it more as a stethoscope. A compiled program is like a black box, but that doesn’t mean we cannot hear what’s inside with the help of strace.

Now that we know what system calls are and how to trace them let’s examine buffered I/O.
Buffered I/O Link to heading
System calls are expensive due to their extra steps, so it’s a good idea to decrease them.
Buffered I/O minimizes the number of system calls when doing I/O operations by temporarily storing the data we read/write inside a buffer.
In real life, we use buffers all the time. We don’t wash one piece of clothing at a time. Instead, we collect all the clothes in a laundry basket(buffer), and when it’s full, we put them in the washing machine and wash them all in one go.

photo: Michael Hession
bufio is the package from the standard library that helps us with buffered I/O.
You should not think that the functions from the io package covered in Part One don’t use buffering because some do. If we check io.Copy, for example, we see that a buffer is internally allocated. What bufio gives us extra are convenient tools for more control over the buffering.
Let’s cover the three main types from the bufio package: bufio.Writer, bufio.Reader and bufio.Scanner.
bufio.Writer Link to heading
Let’s see some writes without buffering:
package main
import (
"os"
)
func main() {
f := os.Stdout // f is a *os.File thus an io.Writer
f.WriteString("a")
f.WriteString("b")
f.WriteString("c")
}
If we compile this program as writer_file and run strace -e write ./writer_file, we get this output containing 3 write system calls:
--- SIGURG {si_signo=SIGURG, si_code=SI_TKILL, si_pid=61172, si_uid=1000} ---
write(1, "a", 1a) = 1
write(1, "b", 1b) = 1
write(1, "c", 1c) = 1
+++ exited with 0 +++
Now let’s try the same code with a buffered writer created by putting the f io.Reader in the bufio.NewWriter(f) function:
package main
import (
"bufio"
"os"
)
func main() {
f := os.Stdout
w := bufio.NewWriter(f)
w.WriteString("a")
w.WriteString("b")
w.WriteString("c")
// Perform 1 write system call
w.Flush()
}
We see the same behavior, but if we run the strace with this compiled program, we have 1 write instead of 3:
--- SIGURG {si_signo=SIGURG, si_code=SI_TKILL, si_pid=61488, si_uid=1000} ---
write(1, "abc", 3abc) = 3
+++ exited with 0 +++
We can see how wrapping an io.Writer into a bufio.NewWriter decreases the number of system calls and how easy is to apply buffering by putting an io.Writer inside only one function.
The reason we had to call w.Flush() was because the bufio.NewWriter function creates a Writer with a default size of 4096 bytes:
// NewWriter returns a new [Writer] whose buffer has the default size.
// If the argument io.Writer is already a [Writer] with large enough buffer size,
// it returns the underlying [Writer].
func NewWriter(w io.Writer) *Writer {
return NewWriterSize(w, defaultBufSize)
}
If data is less than the buffer size, it won’t get written unless we call .Flush(). In our case, we had 3 bytes(abc) < 4096 bytes.
You can customize the size of the buffer by calling NewWriterSize.
In the following example, with a buffer of 3 bytes, abc are printed when we add d. Once we add d, we need to call the Flush() to get it printed because we still have space in the buffer.
package main
import (
"bufio"
"os"
)
func main() {
f := os.Stdout
w := bufio.NewWriterSize(f, 3)
// Will print abc. d is added the buffer and will not be printed without an explicit .Flush()
w.WriteString("a")
w.WriteString("b")
w.WriteString("c")
// -----------------
w.WriteString("d")
}
When adding data to a buffer, there are 3 scenarios:

The buffer has available space -> Data is added to the buffer.
The buffer is full -> Flush(write) the buffer’s content into the io.Writer, and add any new data to the buffer.
The data exceeds the size of the buffer -> Skip the buffer and add data straight to the destination.
package main
import (
"bufio"
"fmt"
)
type Writer int
// Writer implements io.Writer interface
func (w *Writer) Write(p []byte) (n int, err error) {
fmt.Printf("Writing: %s\n", p)
return len(p), nil
}
func main() {
bw := bufio.NewWriterSize(new(Writer), 4)
bw.Write([]byte{'a'}) // buffer has space
bw.Write([]byte{'b'}) // buffer has space
bw.Write([]byte{'c'}) // buffer has space
bw.Write([]byte{'d'}) // buffer has space
bw.Write([]byte{'e'}) // buffer is full. flush `abcd` and add `e` to the buffer
bw.Flush() // flush `e` to underlying Writer
bw.Write([]byte("abcdefghij")) // `abcdefghij` is bigger than 4 so we flush all to underlying Writer
}
bufio.Reader Link to heading
bufio.Reader is similar to bufio.Writer, but instead of buffering data before writing, it buffers data fetched from read system calls, allowing us to read more data in a single read operation.
If we have an io.Reader, we can create a bufio.Reader from it by calling the bufio.NewReader() function with that io.Reader as argument:
var r io.Reader
bufferedReader := bufio.NewReader(r)
Once we have our buffered reader, we can call several read methods on it, such as:

source: https://pkg.go.dev/bufio#Reader
It’s important to remember that any read system call from a buffered reader happens in chunks equal to its internal buffer.
For example, in the following program, we read 4096 bytes at a time, even though we get one byte at a time from the internal buffer:
package main
import (
"bufio"
"fmt"
"io"
"log"
"os"
)
func main() {
fileName := "input.txt"
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("Error opening file: %v", err)
}
defer file.Close()
reader := bufio.NewReader(file)
var bytesRead int64
for {
_, err := reader.ReadByte()
if err != nil && err != io.EOF {
log.Fatalf("Error reading file: %v", err)
}
if err == io.EOF {
break
}
bytesRead++
}
fmt.Printf("Total bytes read with bufio.Reader: %d\n", bytesRead)
}
If we export the output of strace , we will see a bunch of lines like these:
read(3, "The quick brown fox jumps over t"..., 4096) = 4096
read(3, "he quick brown fox jumps over th"..., 4096) = 4096
read(3, "e quick brown fox jumps over the"..., 4096) = 4096
read(3, " quick brown fox jumps over the "..., 4096) = 4096
These lines show that we call read system call every 4096 bytes and not for each byte, even though looking at the method name, ReadByte(), you would think we perform a read for each byte.
That’s the cool stuff about the buffered reader: even if we read smaller chunks in our code, we read from the internal buffer as long as it has elements.
Same as with bufio.Writer, the default buffer size of bufio.Reader is 4096 bytes. If we want to change it, we have the NewReaderSize function.
bufio.Scanner Link to heading
The bufio.Scanner is used to read a stream of data by tokens. Tokens are defined by what separates them. For example, words are tokens split by space, sentences by dots, or lines split by \n character.
Here is an example that reads a file line by line:
package main
import (
"bufio"
"fmt"
"log"
"os"
)
func main() {
f, err := os.Open("input.txt")
if err != nil {
log.Fatal(err)
}
defer f.Close()
s := bufio.NewScanner(f)
for s.Scan() {
fmt.Println(s.Text())
}
if err = s.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading standard input:", err)
}
}
A split function defines the tokens. By default, the bufio.Scanner uses ScanLines split function, which splits tokens into lines.
The standard library offers ScanRunes, ScanWords, and ScanBytes split functions, and you set a split function by calling the .Split() method on the scanner:
package main
import (
"bufio"
"fmt"
"log"
"os"
)
func main() {
f, err := os.Open("input.txt")
if err != nil {
log.Fatal(err)
}
defer f.Close()
s := bufio.NewScanner(f)
s.Split(bufio.ScanWords) // use words as tokens
for s.Scan() {
fmt.Println(s.Text())
}
if err = s.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading standard input:", err)
}
}
If the split functions from the standard library don’t suffice, you can create your own as long as they match the SplitFunc signature:
For example, here is an implementation that splits content by the + sign:
package main
import (
"bufio"
"bytes"
"fmt"
"log"
"strings"
)
func main() {
r := strings.NewReader("a+b+c+d+e")
s := bufio.NewScanner(r)
s.Split(CustomSplit) // set our CustomSplit function to scanner
for s.Scan() {
fmt.Println(s.Text())
}
if err := s.Err(); err != nil {
log.Fatalf("error on scan: %s", err)
}
}
func CustomSplit(data []byte, atEOF bool) (advance int, token []byte, err error) {
if atEOF && len(data) == 0 {
return 0, nil, nil
}
if i := bytes.IndexRune(data, '+'); i >= 0 {
return i + 1, data[0:i], nil
}
if atEOF {
return len(data), data, nil
}
return 0, nil, nil
}
This example is overkill and used only for showcase. When you have a string, you should use the strings.Split() function, or bytes.Split() if you’re dealing with bytes. Use bufio.Scanner only when you deal with files or other data streams, not strings or slices of bytes.
We can see that this bufio.Scanner is a very specialized type of buffered reader that sees data as information split by tokens, and for most cases, you can go with it, but sometimes, when you need more control, you should go with the bufio.Reader instead, as the std library suggests:
Scanning stops unrecoverably at EOF, the first I/O error, or a token too large to fit in the Scanner.Buffer. When a scan stops, the reader may have advanced arbitrarily far past the last token. Programs that need more control over error handling or large tokens, or must run sequential scans on a reader, should use bufio.Reader instead.
Conclusion Link to heading
That was it! It was a long read, but I’m happy to say this article ended our Fundamentals of I/O in Go series.
I hope you liked them and learned something new. It’s normal if you didn’t get everything right from the first read. I suggest you go through them again and try the examples yourself.
If you have questions or want to say Hi!, contact me on LinkedIn.